Discovery of Everyday Human Activities From Long-term Visual Behaviour Using Topic Models
Abstract
Human visual behaviour has significant potential for activity recognition and computational behaviour analysis, but previous works focused on supervised methods and recognition of predefined activity classes based on short-term eye movement recordings. We propose a fully unsupervised method to discover users’ everyday activities from their long-term visual behaviour. Our method combines a bag-of-words representation of visual behaviour that encodes saccades, fixations, and blinks with a latent Dirichlet allocation (LDA) topic model. We further propose different methods to encode saccades for their use in the topic model. We evaluate our method on a novel long-term gaze dataset that contains full-day recordings of natural visual behaviour of 10 participants (more than 80 hours in total). We also provide annotations for eight sample activity classes (outdoor, social interaction, focused work, travel, reading, computer work, watching media, eating) and periods with no specific activity. We show the ability of our method to discover these activities with performance competitive with that of previously published supervised methods.
Download (457.8 Mb)
The data is only to be used for non-commercial scientific purposes. If you use this dataset in a scientific publication, please cite the following paper:
-

Discovery of Everyday Human Activities From Long-term Visual Behaviour Using Topic Models
Proc. ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp), pp. 75-85, 2015.
We were able to record a dataset of more than 80 hours of eye tracking data (see Table 1 for an overview and Figure 1 for sample images). The dataset comprises 7.8 hours of outdoor activities, 14.3 hours of social interaction, 31.3 hours of focused work, 8.3 hours of travel, 39.5 hours of reading, 28.7 hours of computer work, 18.3 hours of watching media, 7 hours of eating, and 11.4 hours of other (special) activities. Note that annotations are not mutually exclusive, i.e. these durations should be seen independently and sum up to more than the actual dataset size. Most of our participants were students and wore the eye tracker through one day of their normal university life. This is reflected in the overall predominant activities, namely focused work, reading, and computer work. Otherwise, as can also be seen from the table, our dataset contains significant variability with respect to participants’ daily routines and consequently the number, type, and distribution of activities that they performed. For example, while P1 wore the eye tracker during a normal working day at the university, P7 and P9 recorded at a weekend and stayed at home all day mainly reading and working on the computer (P7) or watching movies (P9) with little or no social interactions.
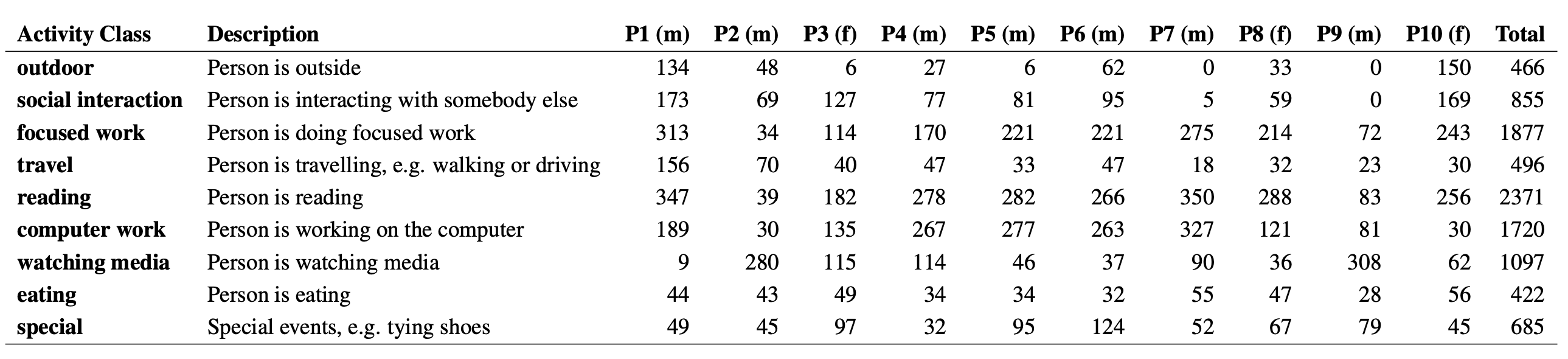
Table 1: Overview of the dataset showing the ground truth annotations, activity descriptions, as well as the amount of data labelled for each activity class in minutes. Note that annotations are non-mutually exclusive, i.e. sum up to more than the actual dataset size. The table also shows the participants’ gender (f: female, m: male).

Figure 1: Sample scene images for each activity class annotated in our dataset showing the considerable variability in terms of place and time of recording. The red dot indicates the gaze location in that particular image.

Figure 2: Recording setup consisting of a laptop with an additional external hard drive and battery pack, as well as a PUPIL head-mounted eye tracker (a). Recording hardware worn by a participant (b).
Apparatus
The recording system consisted of a Lenovo Thinkpad X220 laptop, an additional 1TB hard drive and battery pack, as well as an external USB hub. Gaze data was collected using a PUPIL head-mounted eye tracker connected to the laptop via USB (see Figure 2).. The eye tracker features two cameras: one eye camera with a resolution of 640x360 pixels recording a video of the right eye from close proximity, as well as an egocentric (scene) camera with a resolution of 1280x720 pixels. Both cameras record at 30 Hz. The battery lifetime of the system was four hours. We implemented custom recording software with a particular focus on ease of use as well as the ability to easily restart a recording if needed.
Procedure
We recruited 10 participants (three female) aged between 17 and 25 years through university mailing lists and adverts in university buildings. Most participants were bachelor’s and master’s students in computer science and chemistry. None of them had previous experience with eye tracking. After arriving in the lab, participants were first introduced to the purpose and goals of the study and could familiarise themselves with the recording system. In particular, we showed them how to start and stop the recording software, how to run the calibration procedure, and how to restart the recording. We then asked them to take the system home and wear it continuously for a full day from morning to evening. We asked participants to plug in and recharge the laptop during prolonged stationary activities, such as at their work desk. We did not impose any other restrictions on these recordings, such as which day of the week to record or which activities to perform, etc.
Ground Truth Annotations
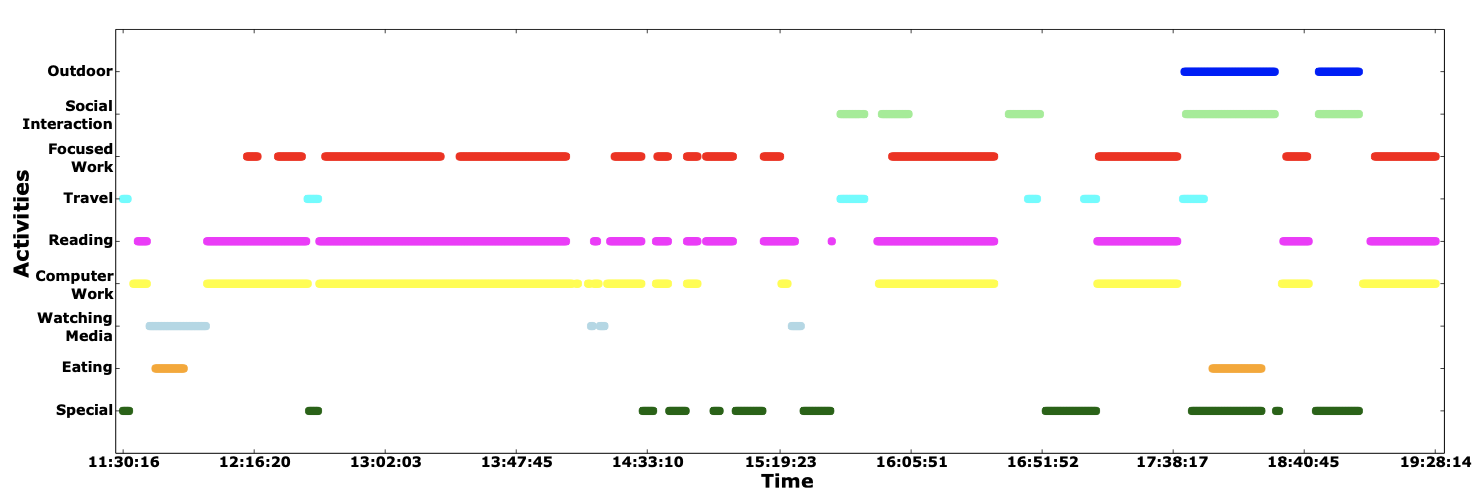
For evaluation purposes, the full dataset was annotated posthoc from the scene videos by a paid human annotator with a set of nine non-mutually-exclusive ground truth activity labels (see Table 1). Specifically, we included labels for whether the participant was inside or outside (outdoor), took part in social interaction, did focused work, travelled (such as by walking or driving), read, worked on the computer, watched media (such as a movie) or ate. We further included a label for special events, such as tying shoes or packing a backpack. This selection of labels was inspired by previous works and includes a subset of activities from [1,2,4]. Figure 3 provides an example of a ground truth labelling of participant 6 over a full day.
Content
The dataset consists of 20 files. Ten files contain the long-term eye movement data of the ten recorded participants of this study. The other ten files describe the corresponding ground truth annotations.
Long-term eye movement recording of participant 1:
| Eye Frame Number | Eye Frame Time | Normalised GazeX | Normalised GazeY | Normalised PupilX | Normalised PupilY | Confidence Value | Ellipse Major | Ellipse Minor | Ellipse Angle |
| 123 | 25591.408231 | 0.543449 | 0.567080 | 0.632791 | 0.446285 | 0.916569 | 62.348351 | 52.137829 | 125.349686 |
| 124 | 25591.439907 | 0.539582 | 0.571380 | 0.634194 | 0.447448 | 0.915689 | 62.362423 | 52.047989 | 124.526283 |
| 125 | 25591.477712 | 0.533799 | 0.579573 | 0.636220 | 0.449711 | 1.000000 | 62.647682 | 51.846684 | 125.090401 |
| 126 | 25591.527972 | 0.528315 | 0.586214 | 0.638157 | 0.451481 | 1.000000 | 62.424488 | 51.700821 | 125.746971 |
| 127 | 25591.569404 | 0.523166 | 0.591113 | 0.640005 | 0.452711 | 1.000000 | 62.404976 | 51.296490 | 125.991196 |
| 128 | 25591.627690 | 0.519758 | 0.593308 | 0.641257 | 0.453192 | 0.902514 | 62.444271 | 51.495365 | 126.859177 |
Ground truth annotation of participant 1:
| Scene Frame Number | Scene Frame Time | Day Time | Activity Label | Activity Description | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 |
| 653927 | 48450.92 | 13:27:30 | eating/social interaction | having lunch/talking to a colleague | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 800660 | 53586.55 | 14:53:06 | reading/focused work | reading paper | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
Method
So far, however, it remains unclear how much information about daily routines is contained in long-term human visual behaviour, how this information can be extracted, encoded, and modelled efficiently, and how it can be used for unsupervised discovery of human activities. The goal of this work is to shed some light on these questions. We collected a new long-term gaze dataset that contains natural visual behaviour of 10 participants (more than 80 hours in total). The data was collected with a state-of-the-art head-mounted eye tracker that participants wore continuously for a full day of their normal life. We annotated the dataset with eight sample activity classes (outdoor, social interaction, focused work, travel, reading, computer work, watching media, and eating) and periods with no specific activity. The dataset and annotations are publicly available online. We further present an approach for unsupervised activity discovery that combines a bag-of-words visual behaviour representation with a latent Dirichlet allocation (LDA) topic model (see Figure 4). In contrast to previous works, our method is fully unsupervised, i.e. does not require manual annotation of visual behaviour. It also does not only extract information from saccade sequences but learns a more holistic model of visual behaviour from saccades, fixations, and blinks.
The specific contributions of this work are three-fold. First, we present a novel ground truth annotated long-term gaze dataset of natural human visual behaviour continuously recorded using a head-mounted video-based eye tracker in the daily life of 10 participants. Second, we propose an unsupervised method for eye-based discovery of everyday activities that combines a bag-of-words visual behaviour representation with a topic model. To this end we also propose different approaches to efficiently encode saccades, fixations, and blinks for topic modelling. Third, we present an extensive performance evaluation that shows the ability of our method to discover daily activities with performance competitive with that of previously published supervised methods for selected activities.

Figure 4: Input to our method are eye movements detected in the eye video. These movements are first encoded into a string sequence from which a bag-of-words representation is generated. The representation is used to learn a latent Dirichlet allocation (LDA) topic model. Output of the model are the topic activations that can be associated with different activities.
References
[1] Bulling, A., Ward, J. A., Gellersen, H., and Tröster, G. Eye Movement Analysis for Activity Recognition Using Electrooculography. IEEE Transactions on Pattern Analysis and Machine Intelligence 33, 4 (2011), 741–753.
[2] Bulling, A., Weichel, C., and Gellersen, H. EyeContext: Recognition of High-level Contextual Cues from Human Visual Behaviour. In Proc. CHI 2013 (2013), 305–308.
[3] Kassner, M., Patera, W., and Bulling, A. Pupil: an open source platform for pervasive eye tracking and mobile gaze-based interaction. In Adj. Proc. UbiComp (2014), 1151–1160.
[4] Shiga, Y., Toyama, T., Utsumi, Y., Kise, K., and Dengel, A. Daily Activity Recognition Combining Gaze Motion and Visual Features. In Adj. Proc. UbiComp (2014), 1103–1111.