Intelligent Autocurricula for Generalization in Cooperative Multi-Agent Reinforcement Learning Environments
Description: While deep Reinforcement Learning has shown promising results in many domains it is still known that RL agents overfit onto the training environment and can't generalize their past experience to new tasks and environments easily [1]. This is especially problematic for agents that aim to cooperate with humans where a failure to generalize results in a failure to cooperate which in turn leads to degraded task performance or worse in safety-critical applications. We are thus interested in improving generalization in cooperative deep multi-agent RL.
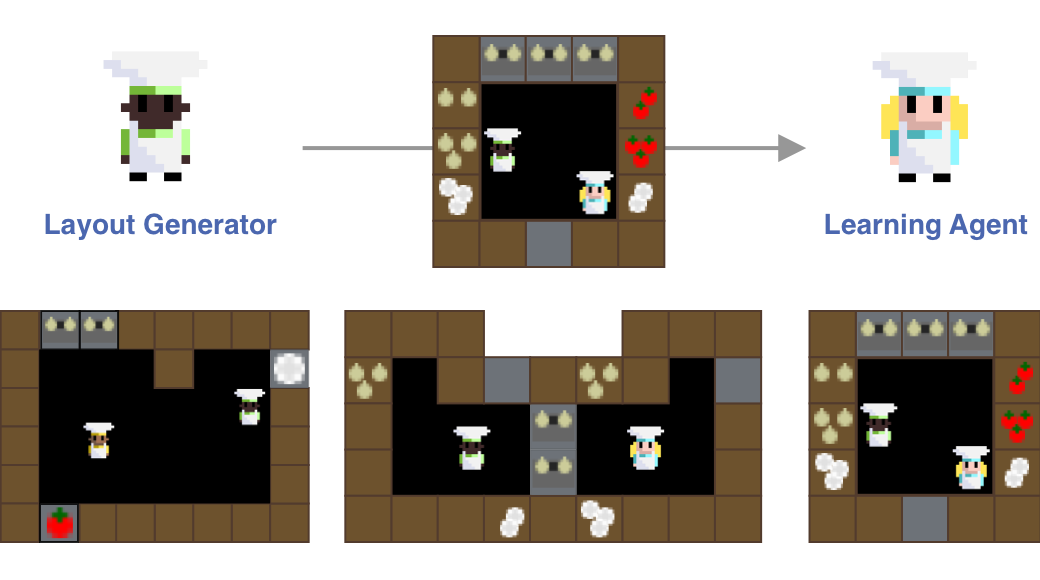
To enable RL agents to generalize to new environments research into unsupervised environment design [2,3] and associated methods (i.e. Prioritized Level Replay [4], also see [3]) aim to find methods that generate suitable levels to learn from and to present them to the learning agent in an order that facilitates optimal learning (so called autocurricula). These works show how important methods for designing autocurricula can be towards generalization but are usually only tested on single agent and simple environments like mazes. In this thesis we want to investigate the importance of these approaches for multi-agent cooperative settings. Specifically, whether these methods allow to build a general capable agent that solves the zero-shot cooperation challenge in the Overcooked-AI environment [5] with humans.
Goal: Implement and extend the concept of autocurricula to multi-agent cooperative environments. Test the approach on our custom version of Overcooked-AI that facilitates play across many layouts. Finally test the agents zero-shot cooperation ability either in a study or with other human agents. If successful this thesis could be featured as a paper at a major conference.
Supervisor: Constantin Ruhdorfer
Distribution: 15% literature review, 70% implementation, 15% analysis
Requirements: Good knowledge of deep learning and reinforcement learning, strong programming skills in Python and PyTorch and/or Jax, self management skills. The thesis requires to learn Jax along the way, experience in PyTorch will be sufficient to start.
Literature: Cobbe, K., Klimov, O., Hesse, C., Kim, T., & Schulman, J. (2019, May). Quantifying generalization in reinforcement learning. In International Conference on Machine Learning (pp. 1282-1289). PMLR.
[2] Dennis, M., Jaques, N., Vinitsky, E., Bayen, A., Russell, S., Critch, A., & Levine, S. (2020). Emergent complexity and zero-shot transfer via unsupervised environment design. Advances in neural information processing systems, 33, 13049-13061.
[3] Jiang, M., Dennis, M., Grefenstette, E., & Rocktäschel, T. (2023). minimax: Efficient Baselines for Autocurricula in JAX. arXiv preprint arXiv:2311.12716.
[4] Jiang, M., Grefenstette, E., & Rocktäschel, T. (2021, July). Prioritized level replay. In International Conference on Machine Learning (pp. 4940-4950). PMLR
[5] Carroll, M., Shah, R., Ho, M. K., Griffiths, T., Seshia, S., Abbeel, P., & Dragan, A. (2019). On the utility of learning about humans for human-ai coordination. Advances in neural information processing systems, 32.